B+Tree
在CMU-DB今年的课程中(2022-fall),实验中要求实现的是基于B+Tree的索引,而不是之前的Extensible Hash Index。毕竟是数据库课程,B+Tree的重要性不言而喻,这边补充学习实现一下。
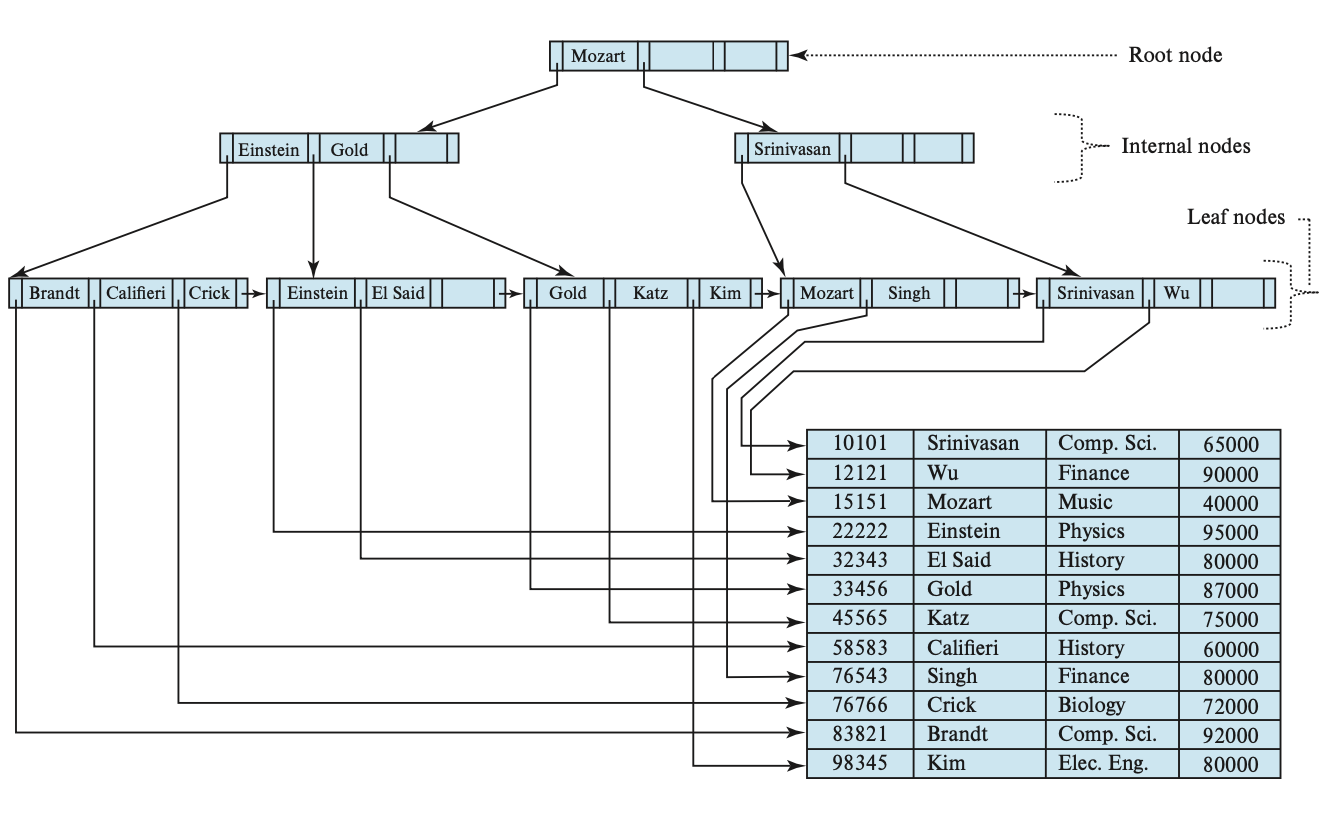
B+Tree for a table
B+Tree的性质
一棵n路平衡搜索树
- It is perfectly balanced (i.e., every leaf node is at the same depth in the tree)
- Every node other than the root is at least half-full N/2-1 ≤ #keys ≤ N-1
- Every inner node with k keys has k+1 non-null children
B-Tree和B+Tree的区别 B-Tree:stored keys and values in all nodes in the tree. (空间利用率高,每个key只在树中出现一次) B+Tree:only stores values in leaf nodes. Inner nodes only guide the search process.
- 注意:下面所有叙述中,索引都是从0开始,便于和实现同步(而不是像课本中的从1开始,给我看懵了)。
B+Tree的两个节点类型
B+Tree内部有两种节点类型,Leaf Node 和 Inner Node。在 Database-System-Concepts-7th-Edition 课本中,Leaf Node和Inner Node 都有一个公共的n值,来确定两种节点的大小相等(Inner Node最多有N个pointer,Leaf Node最多有N个kv-pair),但是在bustub项目中,可以给两种节点设定不同的N值。
Inner Node
Inner Node 节点的数据结构如下。对于max_internal_size == 4的一个B+Inner Node 最多可以保存4个pointer(p0 ~ p3),3个key(k1~k3);最少可以保存(max_internal_size + 1) / 2个pointer,即2个。
每个pointer保存指向树中另外一个节点的所在页的page_id,key用于在当前的节点中进行搜索,搜索时注意k0是无效的。
每个pointer指向下一层中的一个节点(LeafPage或InternalPage)。
假设 p1 指向节点N',N'中包含的所有键 k' 的大小满足 k1 <= k' < k2,
+ - +----+----+----+----+----+----+----+
| k0 | p0 | k1 | p1 | k2 | p2 | k3 | p3 |
+ - +----+----+----+----+----+----+----+
< - >
^
invalid key
实现 在storage/page/b_plus_tree_internal_page中完成对内部节点的定义,注意,在数据库中,一般让一个完整的页作为一个节点,防止太多碎片产生。因此在定义相关头文件的时候,直接将存储键值对的数组设置为跟一个内存页相对应的大小。
Page还会保存一个指向父节点的指针,对于一个父节点指针为空的节点,那么这个节点就是根。注意,两种类型的节点都可以作为根来使用,比如初始的时候只有一个叶子结点,而它就是根。
#define MappingType std::pair<KeyType, ValueType>
#define INTERNAL_PAGE_HEADER_SIZE 24
#define INTERNAL_PAGE_SIZE ((PAGE_SIZE - INTERNAL_PAGE_HEADER_SIZE) / (sizeof(MappingType)))
MappingType array_[INTERNAL_PAGE_SIZE];
Lookup in Inner Node
在内部节点中搜索的时候,由于key都是有序排列,可以用二分法加快搜索。GetSize()返回的是存储的指针数量。
返回的是key值可能出现的节点的指针,即节点内从左到右的所有指针中,最后一个指针所指向的值小于等于key的。
ValueType B_PLUS_TREE_INTERNAL_PAGE_TYPE::Lookup(const KeyType &key, const KeyComparator &comparator) const {
// finding the first index that KeyAt(index) <= key
int left = 0;
int right = GetSize()-1;
int index = GetSize()-1;
while (left <= right) {
int mid = left + ((right - left) >> 1);
if (mid == 0 || comparator(KeyAt(mid), key) <= 0) {
index = mid; // key至少在这个kv pair中
left = mid + 1;
} else {
right = mid - 1;
}
}
return array_[index].second;
}
为了方便往一个满节点插入时不再分配额外的空间,如果对于初始化默认设定的max_internal_page == INTERNAL_PAGE_SIZE时,将max_internal_page -= 1,少保存一个节点,这样在后面Insert的Split时,不需要额外分配空间了,直接向数组的末尾插入即可。Leaf Node的实现也是类似。
Leaf Node
Leaf Node 节点的数据结构如下。对于max_leaf_size = 4的一个B+Tree,Leaf Node 最多可以容纳3个key-value对,即max_leaf_size - 1;最少可以保存max_leaf_size / 2个key-value对。叶节点和内部节点不同的地方是,每个叶节点还保存了个指向相邻右边叶节点的指针,便于对树存储的值进行有序遍历。
B+Tree的叶节点的value可以存储RecordID或者直接存储Tuple。本次实现中存储的是RecordID。
+----+----+----+----+----+----+ +---+
| k0 | v0 | k1 | v1 | k2 | v2 | | p |
+----+----+----+----+----+----+ +---+
^ point to the next leaf
在Leaf Node中所有的时候,返回的是 the first index i such that array[i].first >= key,跟Inner Node有所不同,是因为在实现迭代器的时候,这样的返回可以当作迭代器的End()。
B+Tree的操作
在读取和修改树的节点时,记得使用buffer pool manager来完成内存页的获取和删除、脏页的标注、unused页的Unpin。
Search
搜索操作,即是一个从根到叶的迭代或递归搜索过程,节点内的搜索可以使用二分。
Insert
插入操作涉及到节点的分裂,递归向父节点的插入新的节点的pointer和可用于分开新节点和老节点的key。 具体算法流程可以参照课本实现。我这里只记录在实现过程中需要注意的点。
当一个节点在插入后大小超过了对应的max_size,就需要进行分裂(Split)。
我们这里假定过满的叶节点和内部节点的大小都是n。
关键函数是MoveHalfTo(recipient),此函数要在leaf和inner节点都完成实现。功能是将满节点的一半元素留给自己,另一半按序复制到recipient。这里过满节点的定义是,原本需要开辟新空间的插入,变为直接在满节点中进行插入,因此此时节点的大小就变成合法大小加一。
对于一个过满的节点,将从index=(n+1)/2的位置开始到index=n的所有kv-pair都复制给recipient(recipient从自己的idx=0开始接收kv),剩下的留给自己。
注意这里对于Leaf node和Inner node都是同样的操作,虽然在定义中Inner node的第0个key值无效,但是这里我们仍然需要保存被复制过来的第0个key,因为之后这个key会作为分开新老节点的separate_key插入到父节点中。完成插入父节点后,即可把处于Inner node的第0个key设为invalid。
Delete
删除操作时红黑树中最复杂的操作,对某个节点进行kv-pair删除之后,判断节点的kv-pair数量,如果不再满足半满状态,就要寻找前继节点或后继节点进行合并(Coalesce),合并后递归的在parent中删除对应的key和pointer;如果不能合并(相邻节点的Size和被删节点合并后大小超过了节点最大大小),就与前继节点或者后继节点进行重分配(Redistribute),重分配后要对parent的对应key进行更新。
迭代器
实现在树中按序读取的迭代器。迭代器内部用page_iter记录当前叶节点,key_iter记录当前访问到的 key index。
当page_iter指向最后一个叶节点且key_iter的值为最后一个有效kv-pair的index+1时,即认为是End()。
注意重载的是前缀++运算符重载。
// ++Iterator
INDEX_TEMPLATE_ARGUMENTS
INDEXITERATOR_TYPE &INDEXITERATOR_TYPE::operator++() {
if (!IsEnd()) {
if (key_iter_ < page_iter_->GetSize() - 1) {
key_iter_++;
} else if (page_iter_->GetNextPageId() != INVALID_PAGE_ID) {
LeafPage *next_page = reinterpret_cast<LeafPage *>(bpm_->FetchPage(page_iter_->GetNextPageId()));
bpm_->UnpinPage(page_iter_->GetPageId(), false);
page_iter_ = next_page;
key_iter_ = 0;
} else {
key_iter_++; // make the iterator point to end
}
}
return *this;
}
完成迭代器实现后,就可以通过insert、delete两个test。还有个concurrent task我没做,等以后吧。
root@docker-desktop:/bustub/build# ./test/b_plus_tree_insert_test
Running main() from gmock_main.cc
[==========] Running 2 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 2 tests from BPlusTreeTests
[ RUN ] BPlusTreeTests.InsertTest1
[ OK ] BPlusTreeTests.InsertTest1 (7 ms)
[ RUN ] BPlusTreeTests.InsertTest2
[ OK ] BPlusTreeTests.InsertTest2 (3 ms)
[----------] 2 tests from BPlusTreeTests (11 ms total)
[----------] Global test environment tear-down
[==========] 2 tests from 1 test suite ran. (12 ms total)
[ PASSED ] 2 tests.
root@docker-desktop:/bustub/build# ./test/b_plus_tree_delete_test
Running main() from gmock_main.cc
[==========] Running 2 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 2 tests from BPlusTreeTests
[ RUN ] BPlusTreeTests.DeleteTest1
[ OK ] BPlusTreeTests.DeleteTest1 (8 ms)
[ RUN ] BPlusTreeTests.DeleteTest2
[ OK ] BPlusTreeTests.DeleteTest2 (5 ms)
[----------] 2 tests from BPlusTreeTests (13 ms total)
[----------] Global test environment tear-down
[==========] 2 tests from 1 test suite ran. (14 ms total)
[ PASSED ] 2 tests.
C++相关知识补充
函数模板
在分裂节点的时候,两种类型的节点的分裂逻辑相同,可以用有函数模板的Split来完成,提高代码的可读性。 使用函数模板时要注意,N类型上调用的函数在实际类型上都要被实现,函数签名要相同。
对于leaf节点,MoveHalfTo不需要 buffer_pool_manager ,但为了保持和InternalPage的MoveHalfTo函数签名一致。InternalPage需要 buffer_pool_manager 来完成修改子节点的父指针。
INDEX_TEMPLATE_ARGUMENTS
template <typename N>
N *BPLUSTREE_TYPE::Split(N *node) {
// create new leaf node L' , 插入到L和L的原来右边节点之间
page_id_t page_id;
// 使用模板参数定义page
N *new_page = reinterpret_cast<N *>(buffer_pool_manager_->NewPage(&page_id));
if (new_page == nullptr) {
throw Exception(ExceptionType::OUT_OF_MEMORY, "Cannot alloc new page");
}
// 设置L'的metadata
new_page->Init(page_id, node->GetParentPageId(), node->GetMaxSize());
// 删除所有的L的kv-pairs
// 复制T的一半kv-pairs到L,复制另一半到L'
// test: impl this both in the inner and leaf pages.
node->MoveHalfTo(new_page, buffer_pool_manager_);
return new_page;
}
Cmake
bustub项目中的测试使用google test编写,但不支持stdin读取输入,无法可视化,在今年的仓库中,发现bustub多了一个子目录tools,tools中有 b_plus_tree_printer ,可以make构建二进制。所以我也添加有关目录,增加 b_plus_tree_printer 这个二进制程序。
在项目根目录中的 CMakeList.txt 中增加 add_subdirectory(tools) ,在tools文件夹中创建 CMakeList.txt 和 b_plus_tree_printer.cpp ,CMakeList.txt的内容是如下,注意链接的库名称是 bustub_shared(在2022年的课程代码仓库中名称是bustub)。
set(B_PLUS_TREE_PRINTER_SOURCES b_plus_tree_printer.cpp)
add_executable(b_plus_tree_printer ${B_PLUS_TREE_PRINTER_SOURCES})
target_link_libraries(b_plus_tree_printer bustub_shared)
set_target_properties(b_plus_tree_printer PROPERTIES OUTPUT_NAME b_plus_tree_printer)
重新构建
# at bustub root directory
$mkdir build && cd build
$cmake -DCMAKE_BUILD_TYPE=DEBUG ..
$make b_plus_tree_printer
$./bin/b_plus_tree_printer